Shipping faster with CircleCI pipelines and the Rainforest Orb

Rainforest test failures fall into two broad categories based on what must be done to resolve the failure.
The first category is bugs: your regression test caught a regression! To fix it, you will need to change some code. The second category is “non-bugs”: everything else. Your test might need to be updated, your QA environment might have been misconfigured, or it might just be a flaky failure. For these failures, you should be able to eventually rerun the test and get it to pass without changing any application code.
When fixing a bug, you’ll want to rerun the full suite to ensure that while fixing one regression, you did not introduce another. But if you aren’t changing any code, there is no point in rerunning all the tests that just passed. You’ll just want to rerun the ones that failed and not waste time waiting for tests you know will pass to complete your release.
This is very similar to the kind of failures you can expect in a CI build. Your unit tests might catch a bug, requiring a code change and a brand new build. Or your deploy job might fail because of a network glitch, and you just want to rerun that individual CI job without rerunning all the other jobs in the build.
Limitations of the “Rerun failed tests” button
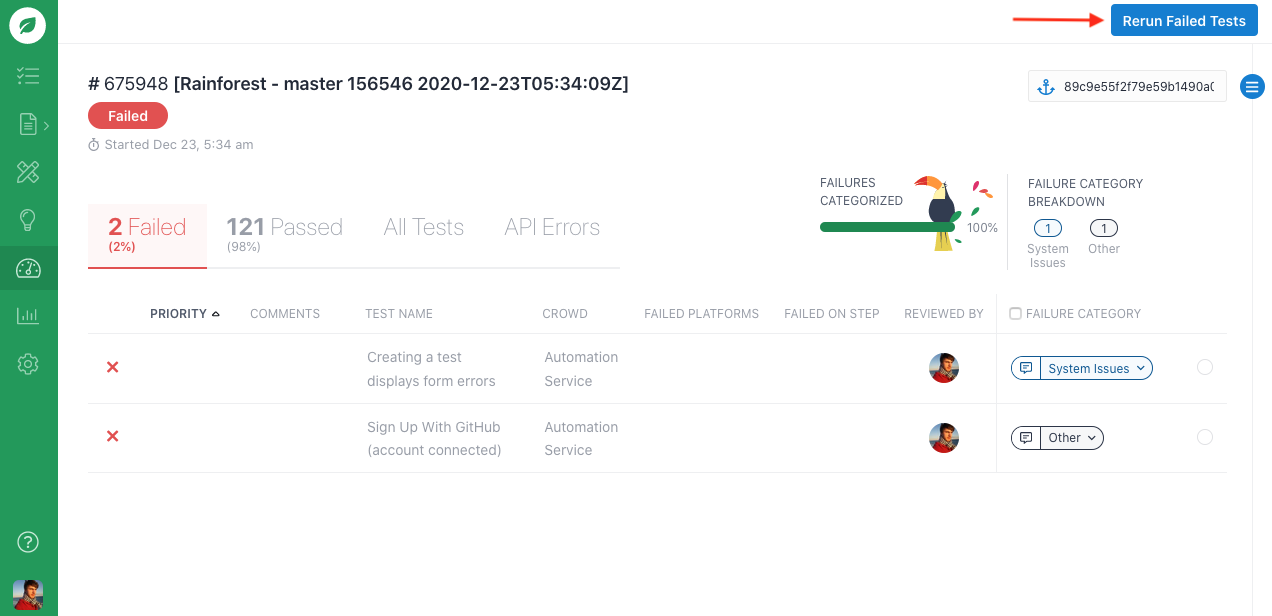
Rainforest has had a “Rerun failed tests” button in our web UI for many years now which did just this, but that button is not useful if you are kicking off your Rainforest runs from a CI environment. You’ll see the reran test pass, but since the run was initialized outside of your CI environment, it won’t know about the run and its result—and your release will remain blocked.
Additional consequences of rerunning all tests
Needing to rerun all tests whenever there’s a failure has a larger impact on release time than appears at first glance. Flaky tests that may have passed the first time around might fail in the rerun, requiring a third run to be kicked off. And if you know ahead of time that a test will fail, you will need to supervise the build to interrupt it after it has deployed to your QA environment, but before the run is triggered—so you can edit the test in question before resuming the build. This was becoming an issue for us internally—our engineers were spending more time supervising and waiting on releases, time that would have been better spent doing something more interesting.
The Rainforest release workflow
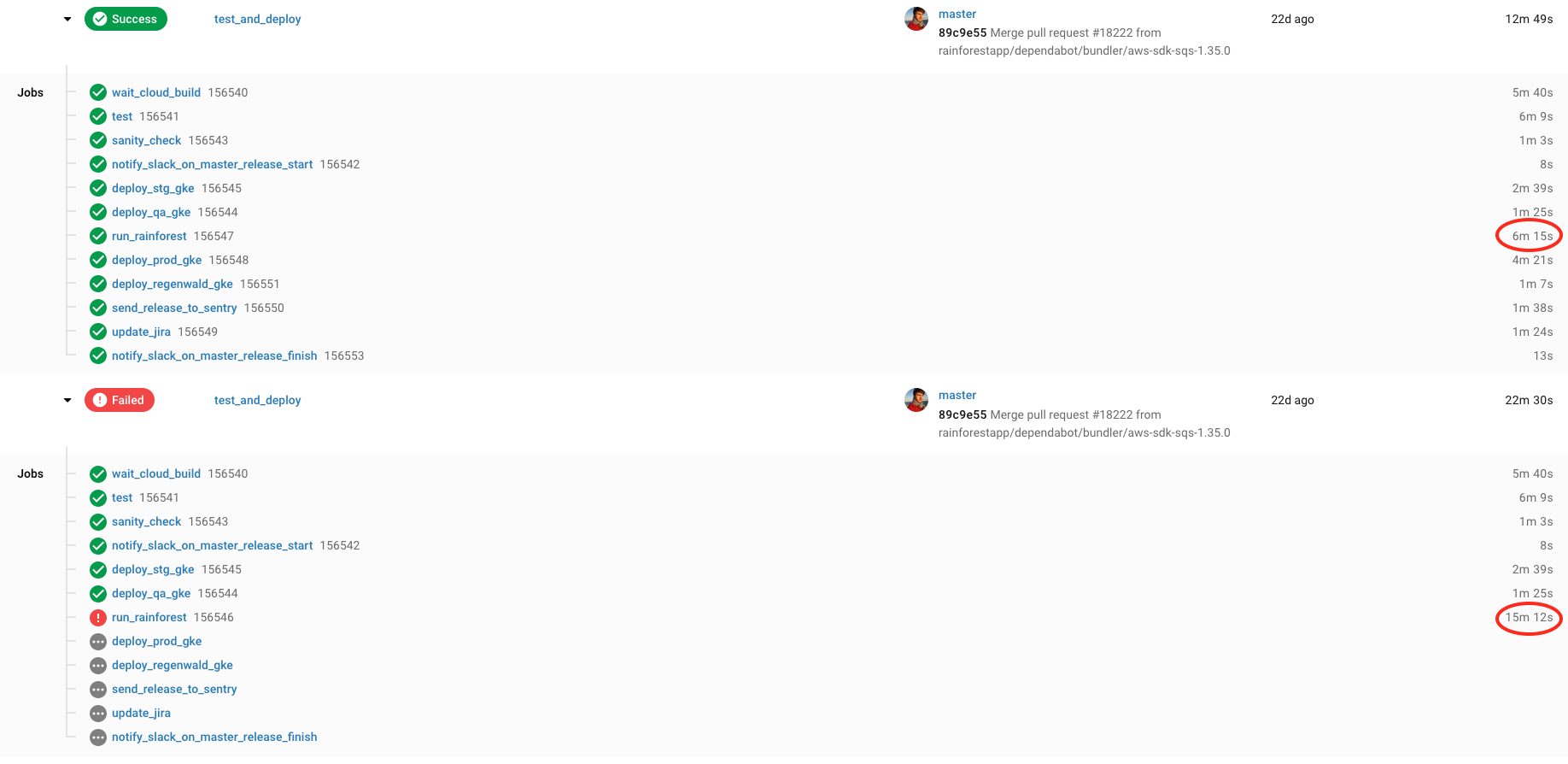
To ship a change, we have a manual PR review, merge to master, and the rest is managed automatically via CI/CD—including running Rainforest tests, which are kicked off via our CircleCI Orb. When the Rainforest run fails (the run_rainforest job in the workflow diagram below), we review the results. If all test failures were due to non-bugs, then once the failures have been resolved (e.g. outdated tests have been updated) we click the “Rerun workflow from failed” button in CircleCI’s web interface to resume our release without having to rerun our unit tests or redeploy to our QA environment.
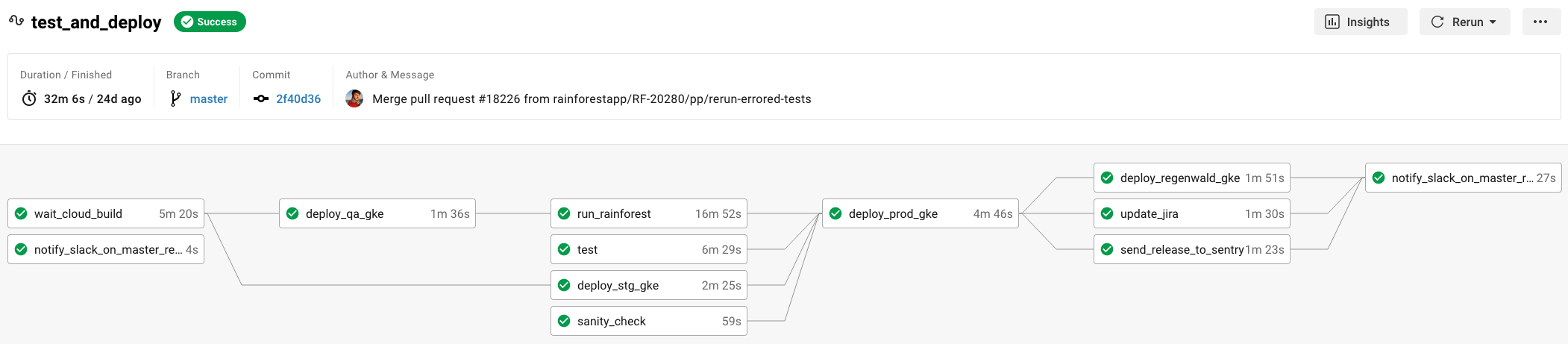
In its original release, the Rainforest Orb was just a simple wrapper around our CLI’s run command. Rerunning the failed workflow meant rerunning the full Rainforest test suite and needlessly delaying our release. We changed this in our v2 release: when rerunning a failed CircleCI workflow with a failed Rainforest run only the failed Rainforest tests will be rerun.
Digging into the v2 code
To understand how this works, there are a couple of CircleCI concepts to figure out: pipelines and caching. In short, pipelines are a way of grouping workflows in CircleCI. If you rerun a failed workflow, that second workflow will be in the same pipeline. If you push a change to trigger a new workflow, that will be in its own pipeline. Using pipelines gives you access to a number of built-in pipeline variables, notably an id variable to know which pipeline we are currently in.
Caching is how CircleCI allows you to persist data across workflows. There are two pieces of data that we need to store when a run fails: the CircleCI pipeline ID and the Rainforest run ID. The save_run_id command does this, saving the run ID in a file named with the pipeline ID, which by default runs when the job has failed. The Rainforest run ID is itself obtained by parsing the JUnit results file created by our CLI once the run has completed.
- run:
name: Save Pipeline and RF Run ID
command: |
mkdir ~/pipeline
xmllint --xpath "string(testsuite/@id)" ~/results/rainforest/results.xml > ~/pipeline/<< parameters.pipeline_id >>
The next step is to then persist that file to the cache, using CircleCI’s built-in save_cache step:
- save_cache:
when: on_fail
key: rainforest-run-{{ .Revision }}-{{ .BuildNum }}
paths:
- ~/pipeline
If you scroll up, you’ll notice that restoring this cache was the first step in this job:
- restore_cache:
keys:
- rainforest-run-{{ .Revision }}-{{ .BuildNum }}
- rainforest-run-{{ .Revision }}-
This means we can now check in the core run_qa command if the current pipeline already had a Rainforest run executed, in which case we’ll try to rerun it rather than create a new run:
# Check for rerun
if [ -n "<< parameters.pipeline_id >>" ] && [ -s ~/pipeline/<< parameters.pipeline_id >> ] ; then
export RAINFOREST_RUN_ID=$(cat ~/pipeline/<< parameters.pipeline_id >>)
echo "Rerunning Run ${RAINFOREST_RUN_ID}"
if ! << parameters.dry_run >> ; then
# Create the rerun
rainforest-cli rerun ...
Since releasing this new feature, we’ve saved untold hours from our releases. Are you a Rainforest customer using CircleCI for your release process? Add our Orb to your CircleCI configuration file to take advantage of this and quicken your releases. Not using CircleCI? We’re working on integrations for other CI/CD platforms—let us know if one would be helpful for your setup.
Interesting? We're looking for hungry hackers who love testing and building tools for other developers. Click here to get in touch.